Lokal LLM i praksis
Kan man faktisk bruke lokal LLM i praksis – eller er det fortsatt mest for entusiaster? For å finne dette ut har Cognitec nylig investert i et profesjonelt skjermkort – NVIDIA RTX 4000 Pro med 24 GB VRAM – som en del av vår satsing på å lære mer om AI, LLM-er og praktisk bruk i utvikling.
Før dette testet vi et Intel Arc Pro B60 (også med 24 GB VRAM), som på papiret fremstod som et spennende og rimelig alternativ. I praksis fungerte det dårlig: ustabile drivere, manglende støtte for viftestyring (støyet som et jetfly) og generelt lav modenhet gjorde at kortet ble returnert. Erfaringen derfra var tydelig – økosystem og driverstøtte betyr mer enn rå spesifikasjoner.

RTX 4000 Pro, basert på Blackwell-arkitektur og CUDA, har derimot levert svært godt så langt.
Arkitektur og oppsett
GPU-en er installert i en av våre Mini-ITX-servere (med den nydelige kassen Fractal-Design Terra) som kjører Proxmox VE. For å få maksimal ytelse har vi satt opp en Ubuntu VM med PCIe passthrough, slik at hele GPU-en dedikeres til én virtuell maskin.
I denne VM-en har vi testet flere ulike inferens-rammeverk (“LLM-motorer”):
Spesielt vLLM har utmerket seg med høy throughput og god støtte for samtidige forespørsler. Ulempen er at den er relativt minnekrevende, spesielt under initialisering, så vi endte i praksis ofte opp med å bruke llama.cpp – selv om den ikke håndterer mange samtidige forespørsler like godt.
Modeller og optimalisering
Vi har eksperimentert med åpne modeller fra Hugging Face, blant annet kinesiske modeller slik som:
For å få plass til større modeller innenfor 24 GB VRAM har vi brukt kvantisering (4-bit og 5-bit). Dette gjør det mulig å kjøre modeller i størrelsesorden 25–35 milliarder parametere lokalt, med akseptabel ytelse.
Dette er en klassisk trade-off:
- lavere presisjon → mindre minnebruk
- men også noe redusert kvalitet
Resultatene er ganske gode for enkle utviklingsoppgaver.
Verktøy og økosystem
Rundt selve modellene har vi satt opp et lite økosystem:
- LiteLLM – proxy som ruter forespørsler til lokale og eksterne modeller
- OpenWebUI – brukervennlig webgrensesnitt for interaksjon med LLM-er
- OpenClaw og Hermes Agent – for agentbasert automatisering
- Integrasjoner mot Slack og Discord
Dette gjør det mulig å bruke LLM-er både via GUI, API og chat – avhengig av behov.
Hvorfor kjøre LLM lokalt?
Den viktigste grunnen er kontroll over data.
Ved lokal kjøring:
- sendes ingen data ut av virksomheten
- unngår man risiko for lekkasje av sensitiv informasjon
- slipper man at input brukes til videre trening hos tredjepart
Dette er spesielt relevant i prosjekter med konfidensiell kode eller kundedata.
Holder 24 GB VRAM?
24 GB VRAM høres mye ut – men føles fort lite når du begynner å pushe grensene.
Man kan ikke kjøre de aller største modellene lokalt, men:
- mindre og mellomstore modeller fungerer bra
- kodegenerering og enklere resonnering går fint
- ytelsen kan være imponerende (80–90 tokens per sekund i våre tester)
Lokal LLM programmerer Snake
Et konkret eksempel: en lokal modell genererte et fullt fungerende JavaScript-spill (“Snake”) på kort tid.
For mer avanserte oppgaver bruker vi fortsatt eksterne modeller, som:
Et interessant eksperiment var å la en kraftigere modell gjøre code review av kode generert av en lokal modell. Resultatet var… ærlig: den var ikke spesielt imponert over lillebror 😄
Under er et utdrag fra en analyse av Snake-spillet som ble generert av en lokal modell (GLM 4.7 flash), og deretter vurdert av en kraftigere modell fra samme leverandør (GLM 5.1) som kjører i skyen:
Dette illustrerer et viktig poeng:
lokale modeller er gode til å produsere kode raskt, men kvaliteten varierer – og bør ofte kvalitetssikres av sterkere modeller eller mennesker.
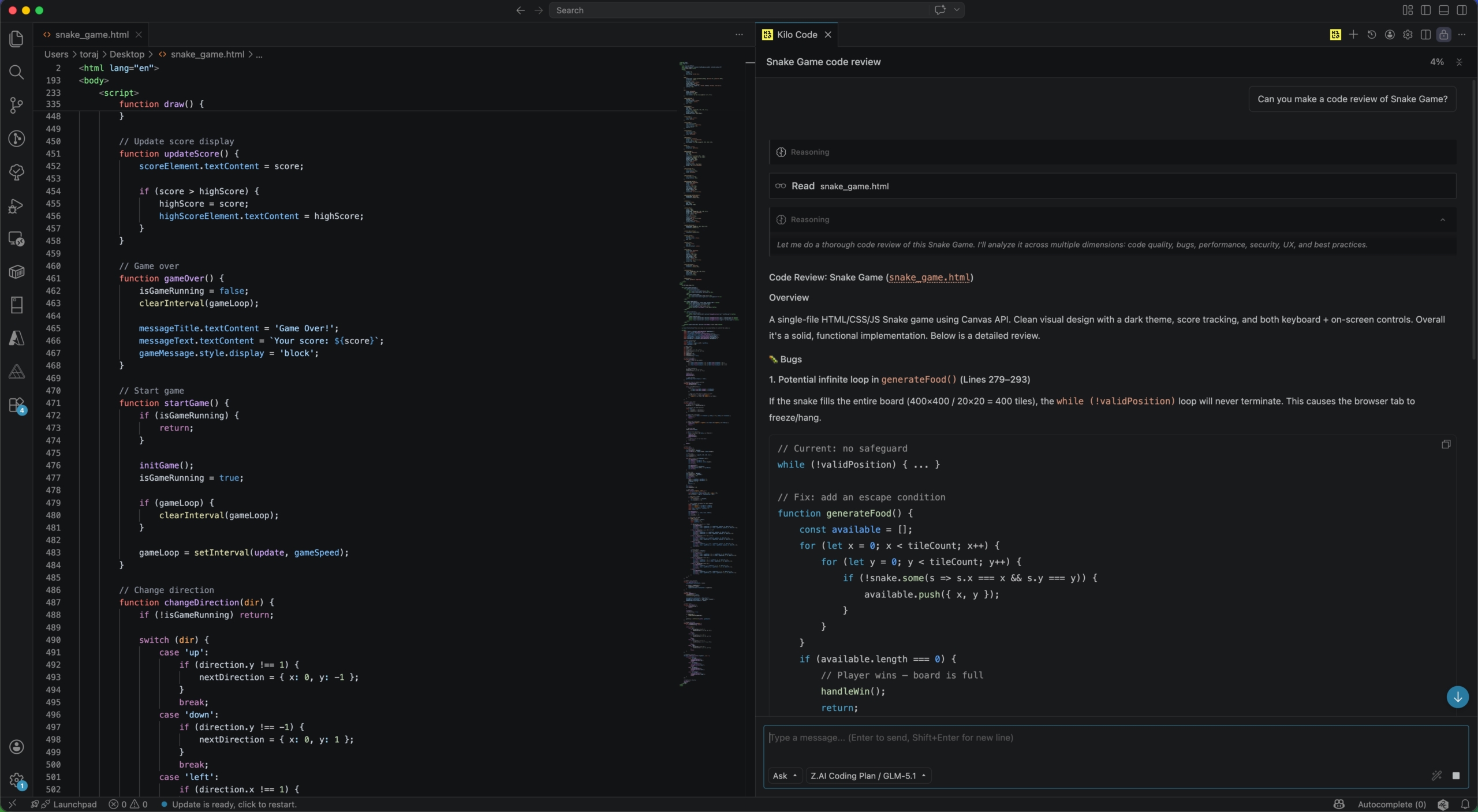
Her ble det som man kan se funnet ganske mange feil og mangler:
Summary Table
# Severity Category Issue
1 🔴 Critical Bug Infinite loop when snake fills board
2 🔴 Critical Bug Direction-reversal race condition
3 🟡 Medium UX High score not persisted across reloads
4 🟡 Medium Perf setInterval causes timing drift
5 🟡 Medium UX/Resp Canvas not responsive on small screens
6 🟡 Medium Compat roundRect() unsupported on older browsers
7 🟠 Low Architecture draw() coupled to update()
8 🟠 Low Feature No pause functionality
9 🟠 Low Feature No win condition
10 🟠 Low CSS Unnecessary !important
11 🟠 Low CSS Duplicated button styles
12 🟠 Low Best Practice Inline onclick handlers
13 🟠 Low Maintainability Magic numbers throughout
14 🟠 Low Rendering Shadow state leak between draw ops
15 🔵 Info Accessibility Missing ARIA labels and live regions
16 🔵 Info UX/Mobile No swipe gesture support
Dette illustrerer et viktig poeng:
lokale modeller er gode til å produsere kode raskt, men kvaliteten varierer – og bør ofte kvalitetssikres av sterkere modeller eller mennesker.
AI har allerede blitt en naturlig del av utviklingshverdagen vår. Vi har testet:
- VS Code med ulike AI-utvidelser
- Cursor
- Copilot CLI
- Claude Code
- OpenCode og Kilo Code
I tillegg til mer agentbasert bruk:
- be en agent klone et Git-repo
- implementere funksjonalitet
- opprette pull requests
…alt via Slack, også når man er ute på tur i marka.
Det høres nesten litt absurd ut, men fungerer overraskende bra.
Oppsummering og konklusjon
Å kjøre LLM-er lokalt har gitt oss:
- et fleksibelt utviklingsverktøy som kan brukes både lokalt og i sky
- bedre forståelse av hvordan modellene faktisk fungerer
- praktisk erfaring med GPU, inferens og optimalisering
For profesjonell bruk er 24 GB VRAM i praksis ganske begrensende, men det er mer enn tilstrekkelig for læring og eksperimentering. Man må samtidig regne med å bruke en del tid på tuning for å få oppsettet stabilt, og utviklingen går så raskt at både modeller og tilhørende verktøy kontinuerlig må oppdateres.
Sterkt kvantiserte åpne modeller på rundt 30 milliarder parametere kan kjøres lokalt med høy token-hastighet, men de er fortsatt langt unna ytelsen til frontier-modeller. Derfor vil man i profesjonelle sammenhenger ofte fortsatt lene seg på skybaserte løsninger, typisk fra leverandører som Anthropic, OpenAI og Google.
Dersom man derimot investerer i kraftigere GPU-er eller maskiner med delt minne, som for eksempel NVIDIA DGX Spark eller Apple Mac Studio i Ultra-konfigurasjon med inntil 512 GB minne, kan lokale LLM-er i større grad nærme seg ytelsen til skybaserte modeller.
For oss har ikke den største verdien ligget i å erstatte skybaserte modeller – men i å forstå dem, kontrollere dem, og bruke dem smartere.
Lokal LLM er ikke en erstatning for skyen. Men det er et ekstremt nyttig verktøy for læring, kontroll og utvikling – spesielt når data ikke kan forlate egen infrastruktur.
Hvis du forventer ChatGPT-nivå lokalt, blir du skuffet.
Hvis du vil forstå og kontrollere AI – er det absolutt verdt det.